

Demos
Piano Concerto Accompaniment Creation

In this project, our vision is to create an orchestral accompaniment for a solo pianist performing a piano concerto. Ideally, the accompaniment would automatically adapt to the pianist's interpretation, adjusting to aspects such as tempo and dynamics. In our project, we have experimented with a first semi-automatic offline approach, as described in the accompanying website. Here, we present the results for two movements of famous piano concertos, where the piano tracks were performed by two non-professional pianists from our research lab, and the orchestral tracks were derived from older, public-domain piano concerto recordings.
Source Separation of Piano Concertos Using Musically Motivated Augmentation Techniques (TASLP)
| In this work, we address the novel and rarely considered source separation task of decomposing piano concerto recordings into separate piano and orchestral tracks. Being a genre written for a pianist typically accompanied by an ensemble or orchestra, piano concertos often involve an intricate interplay of the piano and the entire orchestra, leading to high spectro–temporal correlations between the constituent instruments. Moreover, in the case of piano concertos, the lack of multi-track data for training constitutes another challenge in view of data-driven source separation approaches. As a basis for our work, we adapt existing deep learning (DL) techniques, mainly used for the separation of popular music recordings. In particular, we investigate spectrogram- and waveform-based approaches as well as hybrid models operating in both spectrogram and waveform domains. As a main contribution, we introduce a musically motivated data augmentation approach for training based on artificially generated samples. Furthermore, we systematically investigate the effects of various augmentation techniques for DL-based models. For our experiments, we use a recently published, open-source dataset of multi-track piano concerto recordings. Our main findings demonstrate that the best source separation performance is achieved by a hybrid model when combining all augmentation techniques. | 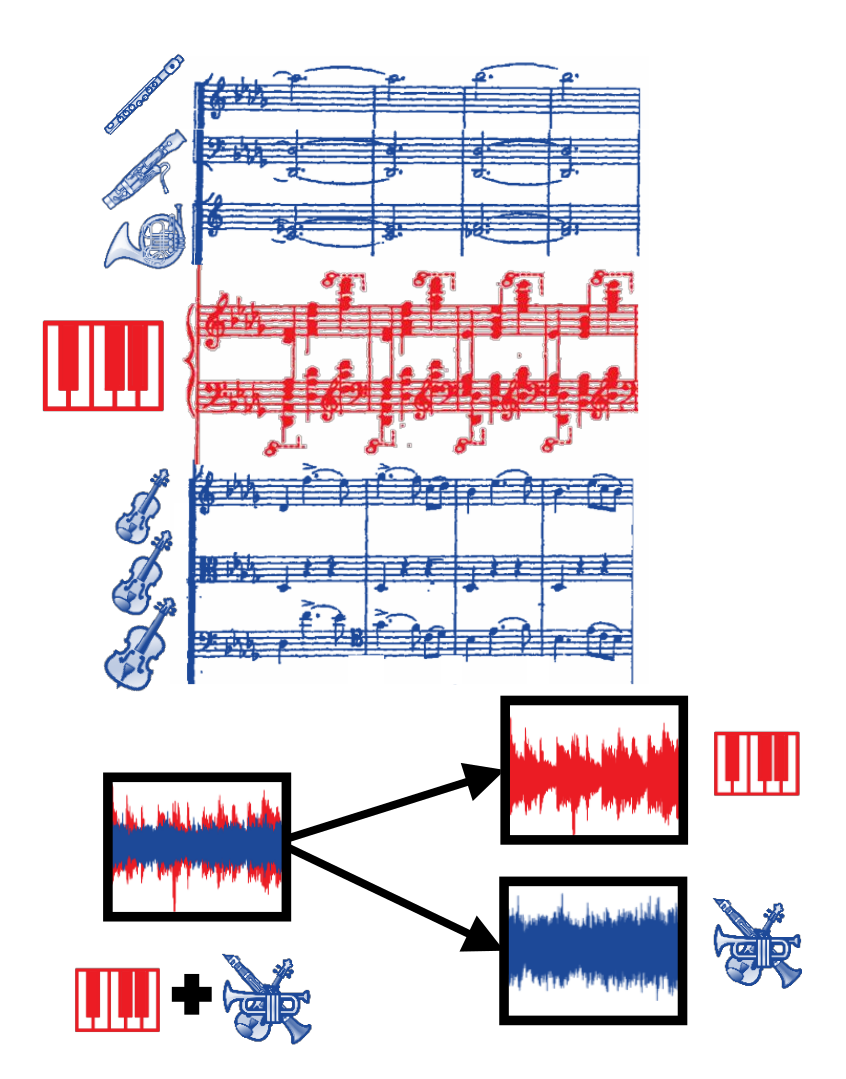 |
Piano Concerto Dataset (PCD): A Multitrack Dataset of Piano Concertos (TISMIR)
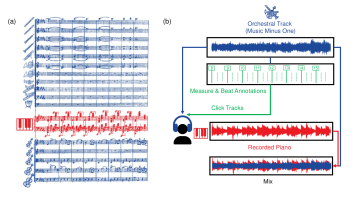
The piano concerto is a genre of central importance in Western classical music, often consisting of a virtuoso solo part for piano and an orchestral accompaniment. In this article, we introduce the Piano Concerto Dataset (PCD), which comprises a collection of excerpts with separate piano and orchestral tracks from piano concertos ranging from the Baroque to the Post-Romantic era. In particular, using existing backing tracks by the music publisher Music Minus One, we recorded excerpts from 15 different piano concertos played by five interpreters on various instruments under different acoustic conditions. The key challenge of playing along with pre-recorded orchestral accompaniments lies in the exact synchronization of the performer. For guiding the pianists for obtaining a high synchronization accuracy, we used additional click tracks generated with measure and beat annotations of the orchestral tracks, which also are provided in the PCD. The dataset is relevant for a variety of Music Information Retrieval (MIR) tasks, including music source separation, automatic accompaniment, music synchronization, editing, and upmixing.
Source Separation of Piano Concertos with Test-Time Adaptation (ISMIR 2022)
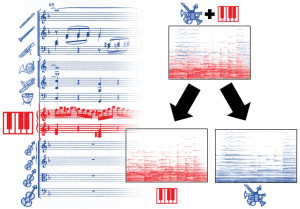
Music source separation (MSS) aims at decomposing a music recording into its constituent sources, such as a lead instrument and the accompaniment. Despite the difficulties in MSS due to the high correlation of musical sources in time and frequency, deep neural networks (DNNs) have led to substantial improvements to accomplish this task. For training supervised machine learning models such as DNNs, isolated sources are required. In the case of popular music, one can exploit open-source datasets which involve multitrack recordings of vocals, bass, and drums. For western classical music, however, isolated sources are generally not available. In this article, we consider the case of piano concertos, which is a genre composed for a pianist typically accompanied by an orchestra. The lack of multitrack recordings makes training supervised machine learning models for the separation of piano and orchestra challenging. To overcome this problem, we generate artificial training material by randomly mixing sections of the solo piano repertoire (e.g., piano sonatas) and orchestral pieces without piano (e.g., symphonies) to train state-of-the-art DNN models for MSS. As our main contribution, we propose a test-time adaptation (TTA) procedure, which exploits random mixtures of the piano-only and orchestra-only parts in the test data to further improve the separation quality.
Sync Toolbox (JOSS)
Sync Toolbox is a Python package, which comprises all components of a music synchronization pipeline that is robust, efficient, and accurate. The toolbox’s core technology is based on dynamic time warping (DTW). Using suitable feature representations and cost measures, DTW brings the feature sequences into temporal correspondence. To account for efficiency, robustness, and accuracy, Sync Toolbox uses a combination of multiscale DTW (MsDTW), memory-restricted MsDTW (MrMsDTW), and high-resolution music synchronization.
libsoni (JOSS)
libsoni is an open-source Python toolbox tailored for the sonification of music annotations and feature representations. By employing explicit and easy-to-understand sound synthesis techniques, the toolbox offers functionalities for generating and triggering sound events, enabling the sonification of spectral, harmonic, tonal, melodic, and rhythmic aspects. Unlike existing software libraries focused on creative applications of sound generation, the toolbox is designed to meet the specific needs of MIR researchers and educators. It aims to simplify the process of music exploration, promoting a more intuitive and efficient approach to data analysis by enabling users to interact with their data in acoustically meaningful ways.
libnmfd / NMF Toolbox (DAFx 2019)
Nonnegative matrix factorization (NMF) is a family of methods widely used for information retrieval across domains including text, images, and audio. Within music processing, NMF has been used for tasks such as transcription, source separation, and structure analysis. Prior work has shown that initialization and constrained update rules can drastically improve the chances of NMF converging to a musically meaningful solution. Along these lines we present the NMF toolbox, containing MATLAB and Python implementations of conceptually distinct NMF variants—in particular, this paper gives an overview for two algorithms. The first variant, called nonnegative matrix factor deconvolution (NMFD), extends the original NMF algorithm to the convolutive case, enforcing the temporal order of spectral templates. The second variant, called diagonal NMF, supports the development of sparse diagonal structures in the activation matrix. Our toolbox contains several demo applications and code examples to illustrate its potential and functionality. By providing MATLAB and Python code on a documentation website under a GNU-GPL license, as well as including illustrative examples, our aim is to foster research and education in the field of music processing.