Speech Coding
Author: Heiko Purnhagen
Co-Author: Bernd Edler
Background information: Coding Distortion
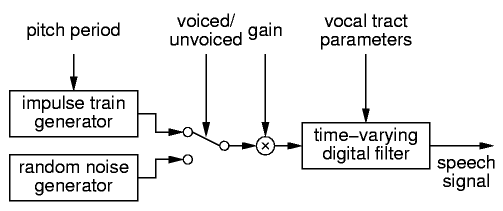
To achieve efficient coding of speech signals at low bitrates, most speech coding systems make use of a model of the speech generation process in the human vocal tract. Figure 1 shows the general structure of such a source model for speech signals [8]. It consists of two alternative excitation generators and a time-varying filter emulating the resonances in the human vocal tract. For voiced sounds, a pulse train with the desired pitch period is used as excitation, while unvoiced sounds use a random noise signal instead.
The time-varying filter is typically implemented as an all-pole filter. The filter coefficients of this IIR filter can be found using linear predictive coding (LPC) techniques [7].
Code Excited Linear Predictive Coding (CELP) is a general and commonly used approach to build a speech coding system based on the speech model shown above [1,2]. Most coders use block-based processing with a frame length of about 10 ms. The excitation for a frame is selected from a set of excitation signals in a codebook. Then, long-term prediction (LTP) can be applied to efficiently model periodic (i.e. voiced) excitation signals with a single pitch (rather than a mixture of different pitch frequencies). This is followed by the time-varying LPC synthesis filter. An adaptive post filter can be added to improve the perceived speech quality. Figure 2 shows a simplified block diagram of a CELP speech decoder.
Typically, encoders employ an analysis-by-synthesis paradigm to find those excitation and predictor parameters that result in the best reconstruction of the signal to be encoded according to a weighted error criterion.

Speech coding applied to non-speech signals?
While speech coders provide a high coding efficiency for speech signals, they are less well suited to code signals that don't fulfill the assumptions about the signal source exploited by such a coding scheme. Thus signals like music are normally conveyed at a significantly lower quality than speech signals.
Some of the problems and their origins are:
- bad modelling of polyphonic or complex signals since only one pitch period is supported
- coding and interpolation of LPC parameters is tuned for speech
- sub-optimal shaping of quantization noise since only a simple perceptual model (weighted error) is used
Sound examples
| Narrowband signals (8 kHz sample rate) |
Original | Coded |
|---|---|---|
| Male Speech | Play | Play |
| Female Speech | Play | Play |
| Vocal Quartet | Play | Play |
| Music A | Play | Play |
| Speech + Music | Play | Play |
| Wideband, Male Speech signals (16 kHz sample rate) |
Original | Coded |
|---|---|---|
| Male Speech | Play | Play |
| Female Speech | Play | Play |
| Vocal Quartet | Play | Play |
| Music A | Play | Play |
| Speech + Music | Play | Play |
References
[1]
W. B. Kleijn, K. K. Paliwal (Eds.): Speech coding and synthesis, Elsevier, 1998.
[2]
B. S. Atal, M. R. Schroeder: "Stochastic Coding of Speech Signals at Very Low Bit Rates,"
Proc. IEEE Int. Conf. on Communications, May 1984, Amsterdam, The Netherlands, p. 48.1.
[3]
R. Steel (Ed.): Mobile Radio Communications, Pentech Press, 1992.
(Chapter 3.5: Analysis-by-synthesis speech coding)
[4]
A. S. Spanias: Speech Coding: A Tutorial Review.
(Portions published in Proceedings of the IEEE, Oct. 1994)
http://www.eas.asu.edu/~spanias/papers/review.ps
[5]
B. Edler: "Speech Coding in MPEG-4,"
International Journal of Speech Technology, Vol. 2, No. 4, pp. 289-303, May 1999.
[6]
M. Nishiguchi: "MPEG-4 speech coding,"
Proc. AES 17th Int. Conference, Signa, Italy, September 1999.
Presentation slides: http://www.tnt.uni-hannover.de/project/mpeg/audio/general/aes17-41-mp4sp.pdf
[7]
J. Makhoul: "Linear Prediction: A Tutorial Review,"
Proc. IEEE, vol. 63, pp 561--580, Apr. 1975.
[8]
L. Rabiner, B.-H. Juang: Fundamentals Of Speech Recognition, Prentice-Hall, 1993.
(Chapter 3.3: Linear predictive coding model for speech recognition)
[9]
Jason Woodard: Speech Coding.
http://www-mobile.ecs.soton.ac.uk/speech_codecs/
[10]
Phil Karn: Digital/Analog Voice Demo.
http://people.qualcomm.com/karn/voicedemo/