Pre-Echo Distortion
Author: Markus Erne
Background information
Most current perceptual audio coding algorithms rely on a block-based process. The motivation for using blocks of data is connected to the transforms which are used in order to split the audio signal into subbands. A perceptual model is used in order to compute the masking threshold for a certain time period. Typical block sizes used in audio coders may range from 400..2048 samples per block. For each block, the subband coding filterbank which can be realized using a transform (MDCT, MLT, ELT, WT), is computed. The masking threshold is estimated using an additional FFT to obtain a complex-valued subband representation. This representation is used to obtain the magnitudes of the subband signals as an input for the psychoacoustic model which computes the masking threshold.
The reasons for processing long blocks of audio are that the necessary side information creates a smaller overhead for larger block sizes and, additionally, slowly varying (almost stationary) signals can be coded more efficiently. The block size directly influences the overall coding delay and may therefore become an important parameter for applications in which a duplex communication between partner is desired.
What is the problem of block processing
Suppose that a time domain transient occurs (e.g. a castanet or triangle attack) during the coding of an current audio block. Since there is substantial signal energy in the attack, the perceptual model will allocate only few bits to each of the quantizers in the subbands because a transient signal in the time domain will spread out in frequency over many subbands.
In the decoder, the subbands samples are reconstructed and the permissible quantization noise, which was supposed to be fully masked, may now spread out in time over the complete block and therefore will also precede the time domain transient. This quantization noise which precedes the transient will cause audible time domain artifacts because it almost "announces" the transient in advance. The quantizaton noise, which is controlled by the psychoacoustic model, has a similar spectral shape as the signal itself. Hence it can be noticed prior to the signal attack as a so-called "Pre-echo".
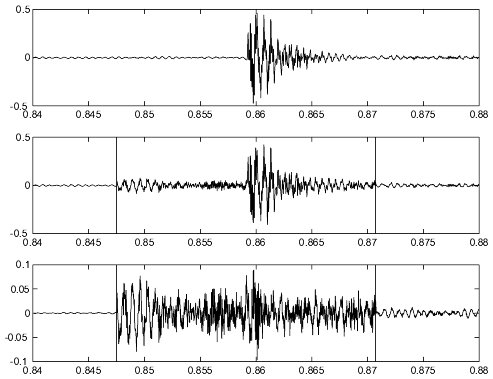
The 3 figures show the original signal on top, the re-quantized signal with the pre-echo, showing the block boundaries and the difference signal between the original and the re-quantized signal.
It can easily be noticed that the quantization error preceding the attack may cause audible artifacts whereas the quantization error during the attack will be masked by the energy of the transient signal.
How to avoid Pre-Echo?
As discussed earlier, short block sizes create a large overhead for the side information and they do not allow to take advantage of long-term stationarity in slowly varying signals. If the block is very short, however, the effect of the pre-echo distortion is smaller and the pre-echo artifacts may be masked due to temporal pre-masking. Therefore more advanced audio coders make use of a technique which is called adaptive block switching [1][2]. A look-ahead of the energy build-up in the next block allows to detect transients and to switch to a smaller block size.
For almost stationary signals, large block sizes are used thereby maximizing the coding gain for most signals. If a transient is detected, the block size is switched to a smaller block size in order to avoid pre-echoes.
Additionally the shape of the window used for the block processing may be altered as well.
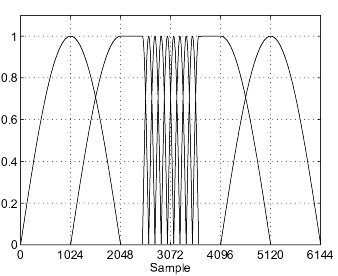
Please refer also to the section on speech reverberation artifacts where similar artifacts might appear.
Sound examples
Pre-echoes mainly appear as disturbing artifact if transient signals (castanets, triangle) are coded. Pre-echoes are most audible if the attack is preceded by a silence or by a signal with a very low energy.
The spectrogram in Figure 3 shows the beginning of the castanets sound example. Note how the transient is smeared into the silent portion at the beginning. Click on the spectrogram to toggle between the original signal and the signal degraded by coding with a block size of 2048 samples.
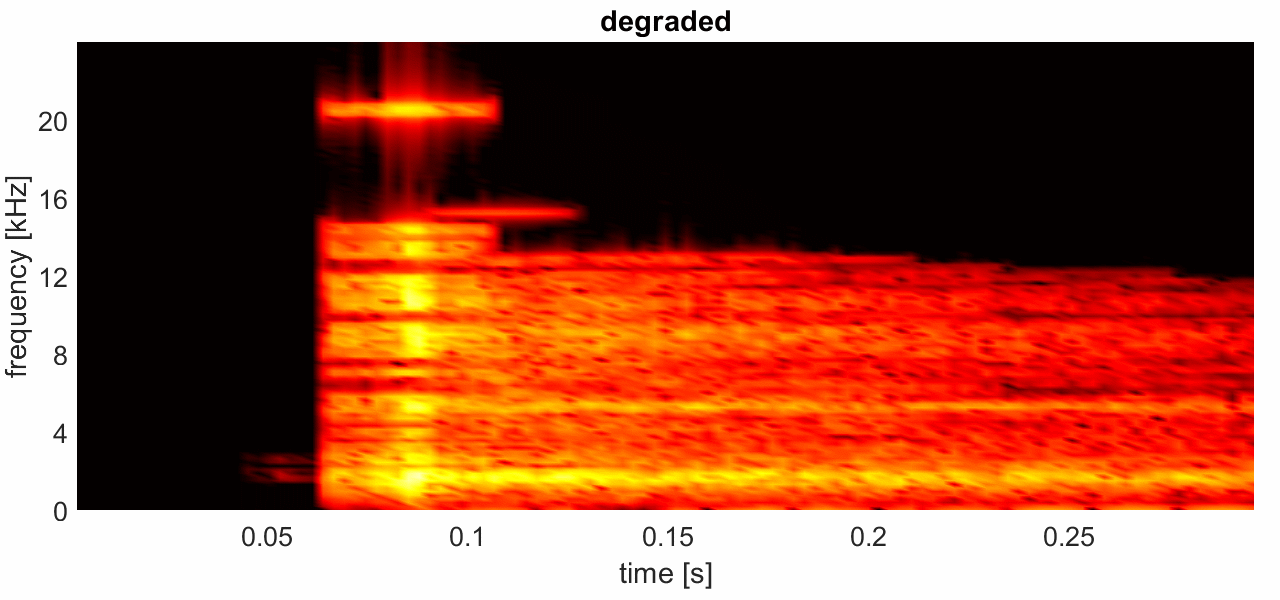
Click on spectrogram to toggle between original and degraded signal.
Keywords
Temporal masking (pre- and postmasking), adaptive block switching, block processing,
Further Reading
Temporal Noise Shaping, (AC-4) Companding, Psychoacoustic models, Speech Reverberation
References
[1] B. Edler: "Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen", Frequenz, Vol. 43, pp. 252-256, 1989
[2] M. Bosi and G. A. Davidson, "High Quality, Low-Rate Audio Transform Coding for Transmission and Multimedia Applications" , 93rd AES Convention, Preprint # 3365, December 1992.
Note: Some of the audio source excerpts have been taken from the SQAM CD [Cat. No. 422204-2] by kind permission of the European Broadcasting Union (EBU)