

A Dataset of Larynx Microphone Recordings for Singing Voice Reconstruction
This is the accompanying website to the article [1].
- Simon Schwär, Michael Krause, Michael Fast, Sebastian Rosenzweig, Frank Scherbaum, and Meinard Müller
A Dataset of Larynx Microphone Recordings for Singing Voice Reconstruction
Transaction of the International Society for Music Information Retrieval (TISMIR), 7(1): 30–43, 2024. PDF Details DOI@article{SchwaerKFRSM24_LarynxMicSVR_TISMIR, author = {Simon Schw{\"a}r and Michael Krause and Michael Fast and Sebastian Rosenzweig and Frank Scherbaum and Meinard M{\"u}ller}, title = {A Dataset of Larynx Microphone Recordings for Singing Voice Reconstruction}, journal = {Transaction of the International Society for Music Information Retrieval ({TISMIR})}, year = {2024}, volume = {7}, number = {1}, pages = {30--43}, doi = {10.5334/tismir.166}, url-pdf = {2024_SchwaerKFRSM_LarynxMicSVR_TISMIR.pdf}, url-details = {https://www.audiolabs-erlangen.de/resources/MIR/LM-SVR/} }
Abstract
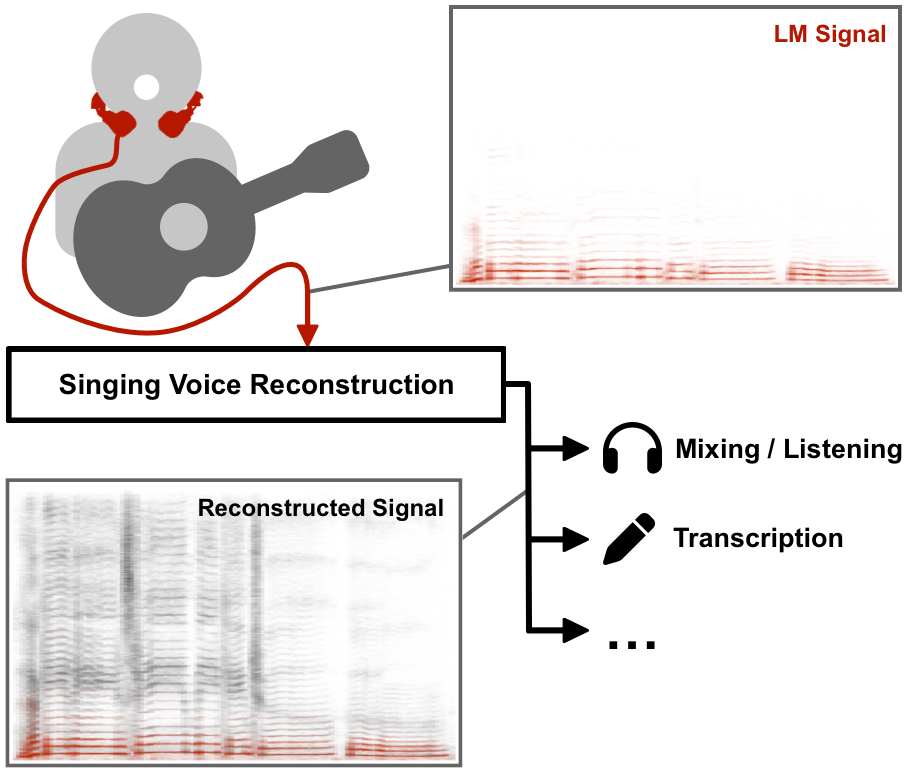
Larynx microphones (LMs) provide a practical way to obtain crosstalk-free recordings of the human voice by picking up vibrations directly from the throat. This can be useful in a multitude of music information retrieval scenarios related to singing, e.g., the analysis of individual voices recorded in environments with lots of interfering noise. However, LMs have a limited frequency range and barely capture the effects of the vocal tract, which makes the recorded signal unsuitable for downstream tasks that require high-quality recordings. In this paper, we introduce the task of reconstructing a natural sounding, high-quality singing voice recording from an LM signal. With an explicit focus on the singing voice, the problem lies at the intersection of speech enhancement and singing voice synthesis with the additional requirement of faithful reproduction of expressive parameters like dynamics and intonation. In this context, we make three main contributions. First, we publish a dataset with over 3.5 hours of popular music we recorded with four amateur singers accompanied by a guitar, where both LM and clean close-up microphone signals are available. Second, we propose a data-driven baseline approach for singing voice reconstruction from LM signals using differentiable signal processing, inspired by a source-filter model that emulates the missing vocal tract effects. Third, we evaluate the baseline with a listening test and further show that it can improve the accuracy of lyrics transcription as an exemplary downstream tasks.
Dataset: LM-SSD
The full dataset with all 348 uncompressed audio files can be downloaded here (ca. 6 GB).
To preview the provided signals for individual songs, please click on "View Song" in the overview table below.
| ID | Song Title | Original Artist | Singer | Duration (mm:ss) | Link |
|---|---|---|---|---|---|
| AA | All Alone | Michael Fast | 1M | 27:03 | View Song |
| TS | The Scientist | Coldplay | 1M | 21:37 | View Song |
| YF | Your Fires | All The Luck In The World | 1M | 24:21 | View Song |
| DL | Dezemberluft | Heisskalt | 2M | 14:47 | View Song |
| BB | Books From Boxes | Maxïmo Park | 2M | 17:39 | View Song |
| NB | Narben | Alligatoah | 2M | 11:47 | View Song |
| SG | Supergirl | Reamonn | 3F, 1M | 26:34 | View Song |
| OC | One Call Away | Charlie Puth | 3F, 1M | 19:32 | View Song |
| PL | Past Life | Trevor Daniel & Selena Gomez | 3F, 1M | 17:45 | View Song |
| CC | Chasing Cars | Snow Patrol | 4F | 28:10 | View Song |
| BT | Breakfast At Tiffany's | Deep Blue Something | 4F | 22:16 | View Song |
| LL | Little Lion Man | Mumford & Sons | 4F | 19:06 | View Song |
Baseline LM-SVR System: Reconstruction Results
The following example excerpts are presented as used in the listening test. The used train/test splits for each take can be downloaded here.
Example I (1M)
Example II (2M)
Example III (3F)
Example IV (4F)
Acknowledgments
We would like to thank the musicians for their contribution to the dataset and Daniel Vollmer for his help with the LMs. The International Audio Laboratories Erlangen are a joint institution of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and Fraunhofer Institute for Integrated Circuits IIS. This project is supported by the German Research Foundation (DFG MU 2686/13-2).
License
The recordings in LM-SSD are available under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.
Note that some songs in the dataset are cover versions. In these cases, it may be required to obtain a separate license for the composition, depending on the intended use case.