

Low-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Kishor Kayyar Lakshminarayana, Frank Zalkow, Christian Dittmar, Nicola Pia, Emanuël A.P. Habets
Abstract
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
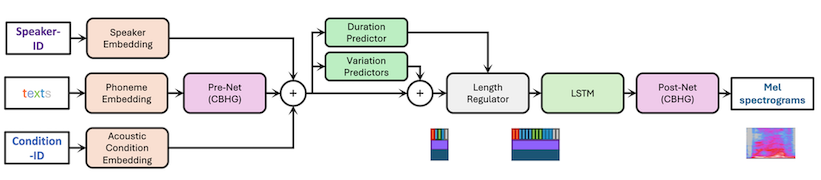
Proposed Method
ICASSP2025 Video
Audio Examples
The following audio examples are synthesized with different text-to-speech models. Only the TC-Star speaker has been used here as example.
- High-Resource: ForwardTacotron model trained with 5 High-Resources (HR) speakers including 5.5 hours of TC-Star.
- Proposed (20 min) : Our model trained with 4 HR speakers and a twenty minute subset of TC-Star set using proposed sampling approaches and noise augmentation.
- Proposed (5 min) : Our model trained with 4 HR speakers and a five minute subset of TC-Star set using proposed sampling approaches and noise augmentation.
- Proposed (1 min) : Our model trained with 4 HR speakers and an one minute subset of TC-Star set using proposed sampling approaches and noise augmentation.
- AdapterMix : AdapterMix[4] model finetuned using the same twenty minute TC-Star subset as "Proposed (20 min)".
- HierSpeech++ : A pretrained HierSpeech++[5] model using a 20 second long TC-Star target input.
The text used to synthesize the samples and the audio examples are below. All the files (except AdapterMix and HierSpeech++) were synthesized using a pretrained StyleMelGAN vocoder [3]. AdapterMix and HierSpeech++ both used the vocoders part of their respective public repositories.
Oak is strong and also gives shade.
Cats and dogs each hate the other.
The pipe began to rust while new.
A lame back kept his score low.
We find joy in the simplest things.
Ducks fly north but lack a compass.
Additional Material
- Poster used in the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) held at Hyderabad, India, on 6-11 April, 2025 (PDF)
References
- Christian Schäfer, Ollie McCarthy, and contributors
ForwardTacotron
https://github.com/as-ideas/ForwardTacotron, 2020.@misc{Schaefer20_ForwardTacotron_Github, author = {Christian Schäfer and Ollie McCarthy and contributors}, howpublished = {\url{https://github.com/as-ideas/ForwardTacotron}}, journal = {GitHub repository}, publisher = {GitHub}, title = {{ForwardTacotron}}, year = {2020} } - Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, Rif A. Saurous, Yannis Agiomvrgiannakis, and Yonghui Wu
Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions
In Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP): 4779–4783, 2018. DOI@inproceedings{shen_natural_2018, title = {Natural {TTS} synthesis by conditioning wavenet on {MEL} spectrogram predictions}, author = {Jonathan Shen and Ruoming Pang and Ron J. Weiss and Mike Schuster and Navdeep Jaitly and Zongheng Yang and Zhifeng Chen and Yu Zhang and Yuxuan Wang and Rj Skerrv-Ryan and Rif A. Saurous and Yannis Agiomvrgiannakis and Yonghui Wu}, booktitle = {Proc. {IEEE} Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP)}, year = 2018, pages = {4779--4783}, isbn = {978-1-5386-4658-8}, doi = {10.1109/ICASSP.2018.8461368}, } - Ahmed Mustafa, Nicola Pia, and Guillaume Fuchs
StyleMelGAN: An efficient high-fidelity adversarial vocoder with temporal adaptive normalization
In Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP): 6034–6038, 2021.@inproceedings{mustafa2021stylemelgan, title={{StyleMelGAN}: An efficient high-fidelity adversarial vocoder with temporal adaptive normalization}, author={Ahmed Mustafa and Nicola Pia and Guillaume Fuchs}, booktitle={Proc. {IEEE} Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP)}, pages={6034--6038}, year={2021} } - Ambuj Mehrish, Abhinav Ramesh Kashyap, Li Yingting, Navonil Majumder, and Soujanya Poria
AdapterMix: Exploring the efficacy of mixture of adapters for low-resource TTS adaptation
In interspeech: 4284–4288, 2023. DOI@inproceedings{mehrish23_interspeech_adaptermix, author={Ambuj Mehrish and Abhinav {Ramesh Kashyap} and Li Yingting and Navonil Majumder and Soujanya Poria}, title={{AdapterMix: Exploring the efficacy of mixture of adapters for low-resource TTS adaptation}}, year=2023, booktitle=interspeech, pages={4284--4288}, doi={10.21437/Interspeech.2023-1568} } - Sang-Hoon Lee, Ha-Yeong Choi, Seung-Bin Kim, and Seong-Whan Lee
HierSpeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis
arXiv preprint arXiv:2311.12454, 2023.@article{lee2023_arxiv_hierspeech++, title={HierSpeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis}, author={Sang-Hoon Lee and Ha-Yeong Choi and Seung-Bin Kim and Seong-Whan Lee}, journal={arXiv preprint arXiv:2311.12454}, year={2023} }