

A Variational Y-Autoencoder for Disentangling Gesture and Material of Interaction Sounds
This is the accompanying website to the article [1].
- Simon Schwär, Meinard Müller, and Sebastian J. Schlecht
A Variational Y-Autoencoder for Disentangling Gesture and Material of Interaction Sounds
In AES 4th International Conference on Audio for Virtual and Augmented Reality (AES AVAR), 2022. Demo Code@inproceedings{SchwaerMS_InteractionSounds_AVAR, author = {Simon Schw{\"a}r and Meinard M{\"u}ller and Sebastian J. Schlecht}, title = {A Variational Y-Autoencoder for Disentangling Gesture and Material of Interaction Sounds}, booktitle = {{AES} 4th International Conference on Audio for Virtual and Augmented Reality ({AES AVAR})}, address = {Redmond, WA, USA}, year = {2022}, url-demo = {https://www.audiolabs-erlangen.de/resources/2022-AVAR-InteractionSounds}, url-code = {https://github.com/simonschwaer/adagio-for-things} }
An implementation of the presented work is available on GitHub (external link).
Abstract
Appropriate sound effects are an important aspect of immersive virtual experiences. Particularly in mixed reality scenarios it may be desirable to change the acoustic properties of a naturally occurring interaction sound (e.g., the sound of a metal spoon scraping a wooden bowl) to a sound matching the characteristics of the corresponding interaction in the virtual environment (e.g., using wooden tools in a porcelain bowl). In this paper, we adapt the concept of a Y-Autoencoder (YAE) to the domain of sound effect analysis and synthesis. The YAE model makes it possible to disentangle the gesture and material properties of sound effects with a weakly supervised training strategy where only an identifier label for the material in each training example is given. We show that such a model makes it possible to resynthesize sound effects after exchanging the material label of an encoded example and obtain perceptually meaningful synthesis results with relatively low computational effort. By introducing a variational regularization for the encoded gesture, as well as an adversarial loss, we can further use the model to generate new and varying sound effects with the material characteristics of the training data, while the analyzed audio signal can originate from interactions with unknown materials.
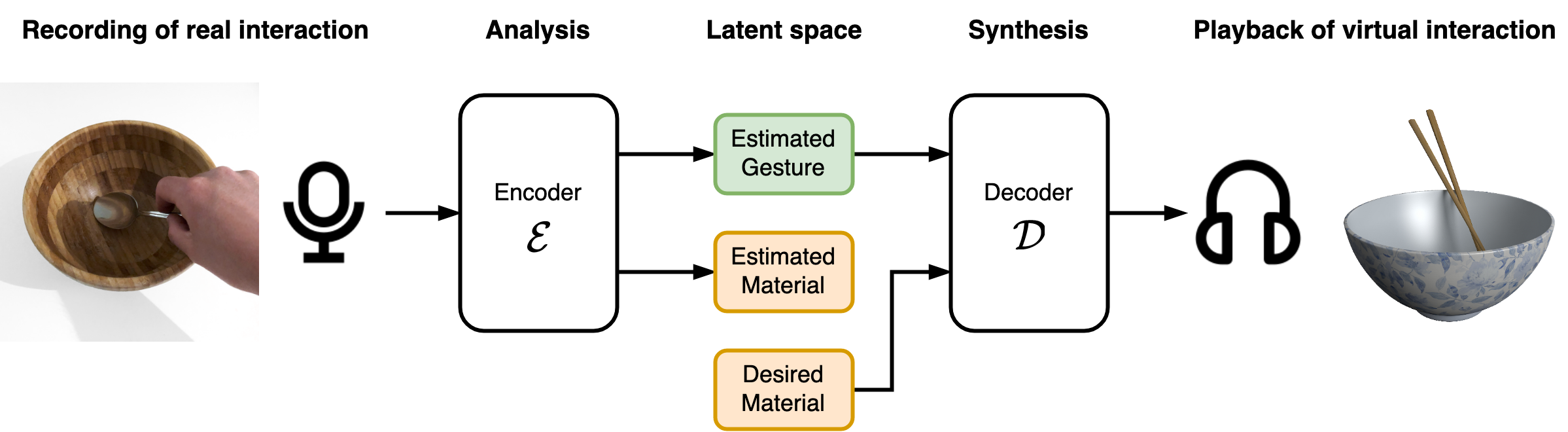
Video demonstration
This video demonstrates a possible use case of the system. We use the sounds of an interaction between an HTC Vive controller and a table as input for our model trained on the Spoon/Bowl dataset. The raw cell phone microphone signal is resampled to 16 kHz sampling rate and processed frame-wise by the model. No other normalization or processing is done with the audio track of the video.
Audio Examples
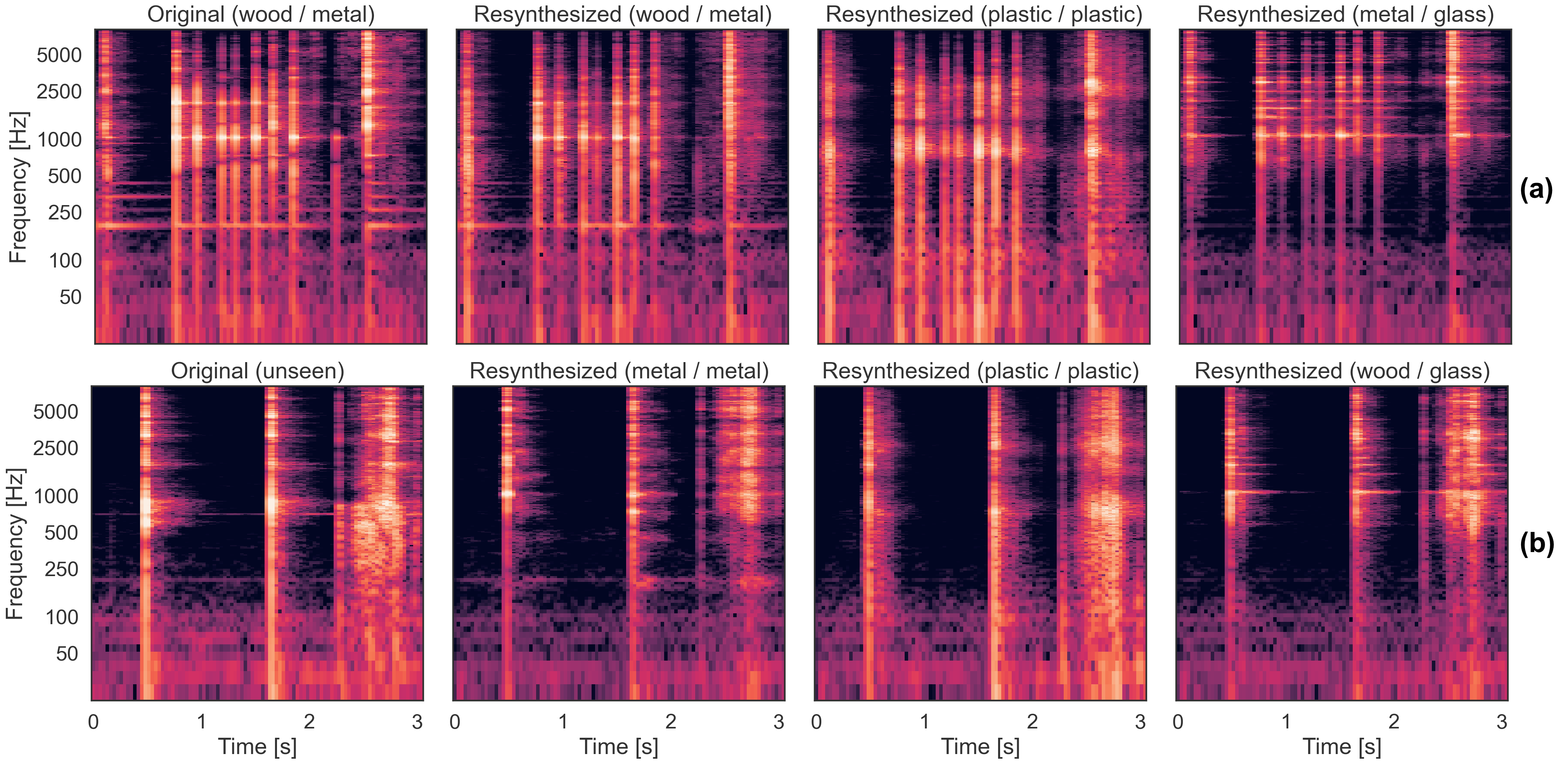
Spoon/Bowl dataset
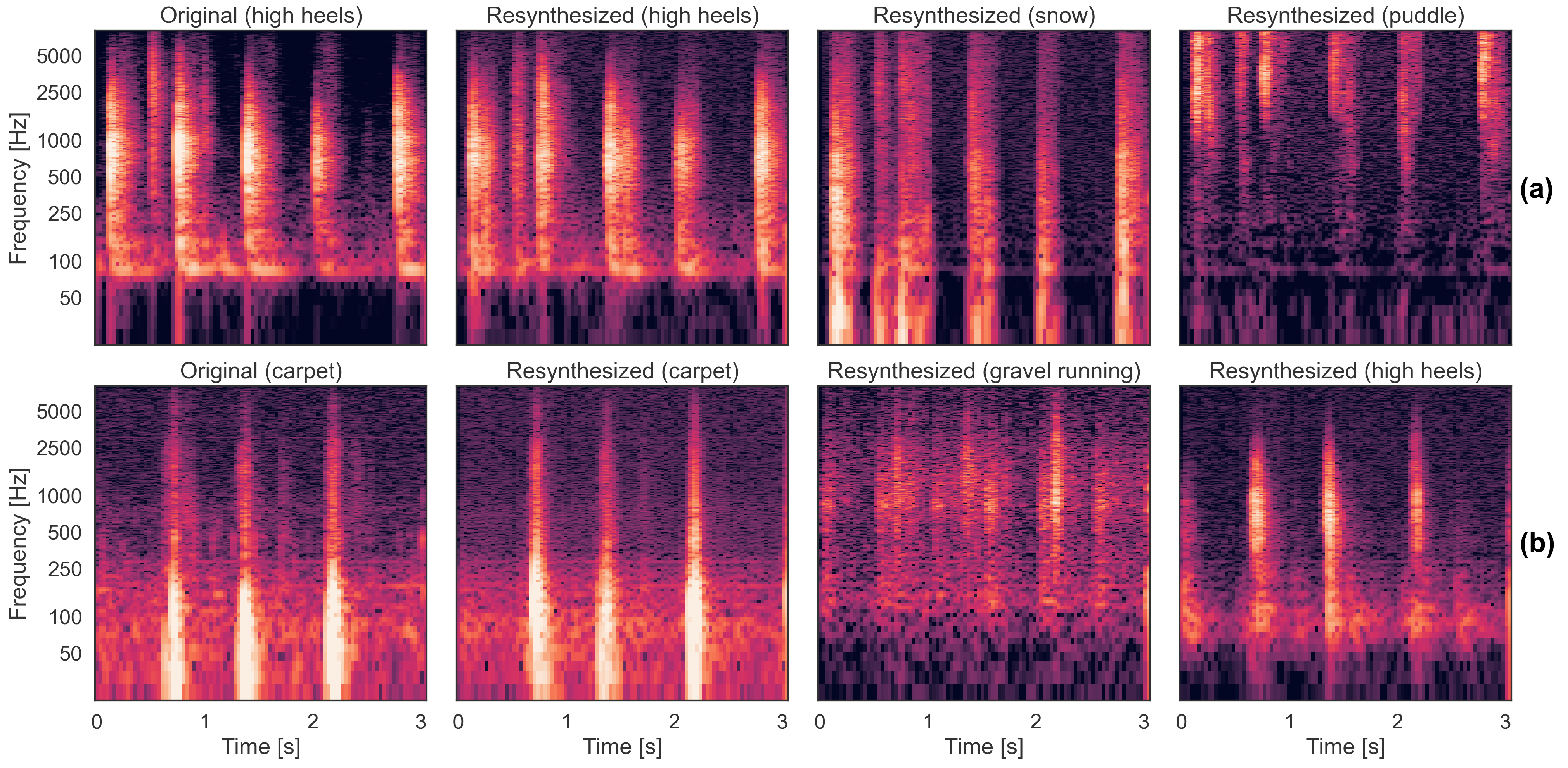
Freesound Footsteps dataset
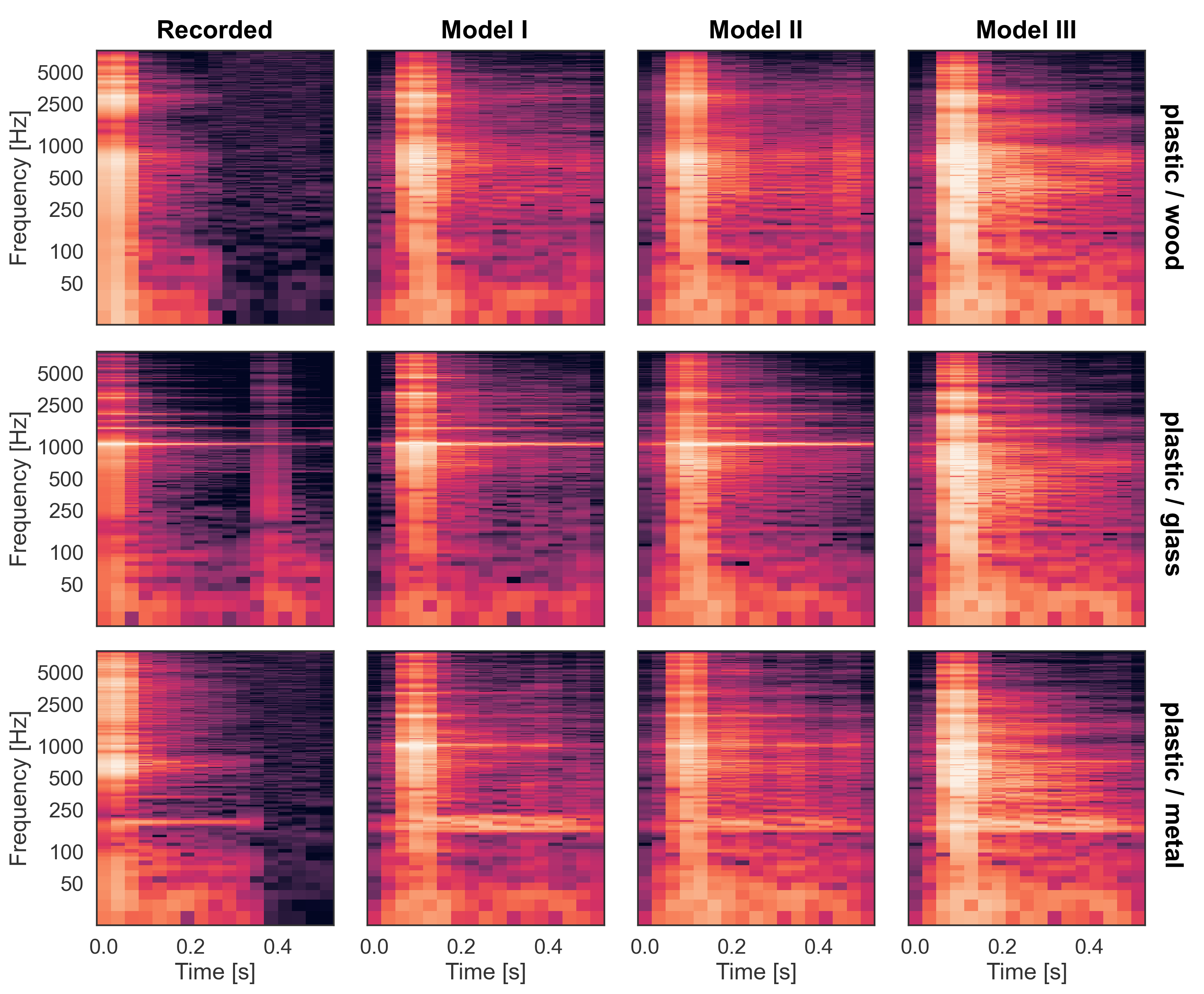
Short impacts Spoon/Bowl dataset
Acknowledgments
During this project, Simon Schwär was supported by a fellowship within the IFI programme of the German Academic Exchange Service (DAAD). The International Audio Laboratories Erlangen are a joint institution of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and Fraunhofer Institute for Integrated Circuits IIS.