

A flow-based neural network for time domain speech enhancement
Martin Strauss and Bernd Edler
published at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021
Abstract
| Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding helps to improve the model performance by expanding the range of learnable values. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics. |
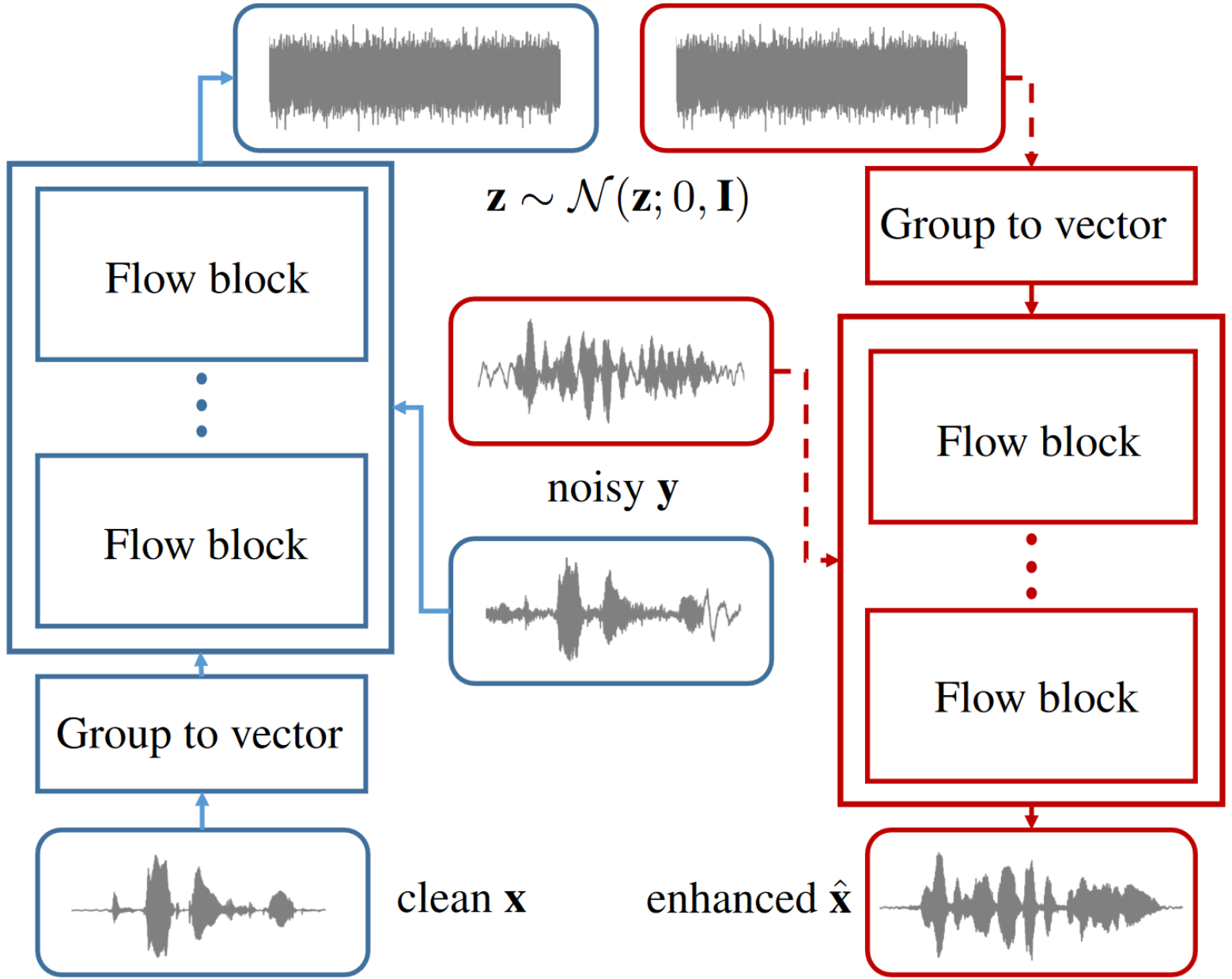
|
Examples
Listening examples from the testset published by Valentini et al. [1]. The dataset can be downloaded here. There are three examples per SNR level and test speaker. In addition, samples from the SEGAN [2] model were added for comparison. The code to create the SEGAN samples can be found here.
ID |
Gender |
Noise |
SNR [dB] |
Website |
|---|---|---|---|---|
| p232_005 | male | Bus | 2.5 | Link |
| p232_034 | male | Living room | 12.5 | Link |
| p232_062 | male | Public square | 12.5 | Link |
| p232_081 | male | Public square | 17.5 | Link |
| p232_097 | male | Office | 17.5 | Link |
| p232_219 | male | Cafè | 7.5 | Link |
| p232_225 | male | Office | 2.5 | Link |
| p232_234 | male | Public square | 2.5 | Link |
| p232_253 | male | Public square | 7.5 | Link |
| p232_282 | male | Cafè | 7.5 | Link |
| p232_284 | male | Living room | 17.5 | Link |
| p232_380 | male | Bus | 12.5 | Link |
| p257_040 | female | Public square | 12.5 | Link |
| p257_041 | female | Public square | 7.5 | Link |
| p257_081 | female | Public square | 7.5 | Link |
| p257_091 | female | Living room | 17.5 | Link |
| p257_130 | female | Cafè | 2.5 | Link |
| p257_177 | female | Office | 12.5 | Link |
| p257_218 | female | Office | 7.5 | Link |
| p257_233 | female | Living room | 12.5 | Link |
| p257_323 | female | Public square | 2.5 | Link |
| p257_368 | female | Cafè | 17.5 | Link |
| p257_384 | female | Bus | 17.5 | Link |
| p257_395 | female | Living room | 2.5 | Link |
References
[1] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Speech enhancement for a noise-robust text-to-speech synthe-sis system using deep recurrent neural networks,” in Proceedings Interspeech Conference, 2016, pp. 352–356.
[2] S. Pascual, A. Bonafonte, and J. Serrà, “SEGAN: Speech Enhancement Generative Adversarial Network,” in Proceedings Interspeech Conference, 2017, pp. 3642–3646.