

Signal-Guided Source Separation
W. Mack, M. Elminshawi and E. A. P. Habets
Abstract
State-of-the-art separation of desired signal components from a mixture is achieved using time-frequency masks or filters estimated by a deep neural network (DNN). The desired components, thereby, are typically defined at the time of training. Recent approaches allow determining the desired components during inference via auxiliary information. Auxiliary information is, thereby, extracted from a reference snippet of the desired components by a second DNN, which estimates a set of adaptive weights (AW) of the first DNN. However, the AW methods require the reference snippet and the desired signal to exhibit time-invariant signal characteristics (SC) and have only been applied for speaker separation. We show that these AW methods can be used for universal source separation and propose an AW estimation method to extract time-variant auxiliary information from the reference signal. That way, the SCs are allowed to vary across time in the reference and mixture. Applications where the reference and desired signal cannot be assigned to a specific class and vary over time require a time-dependency. An example is acoustic echo cancellation, where the reference is the loudspeaker signal. To avoid strong scaling between the estimate and the mixture, we propose the dual scale-invariant signal-to-distortion ratio in a TASNET inspired DNN as the training objective. We evaluate the proposed AW systems using a wide range of different acoustic conditions and show the scenario dependent advantages of time-variant over time-invariant AW.
Note that all following signals in Examples 1-5 have been normalized in loudness to improve the listening experience according to EBU R128 with https://github.com/slhck/ffmpeg-normalize
Example 1: Speaker vs. Speaker
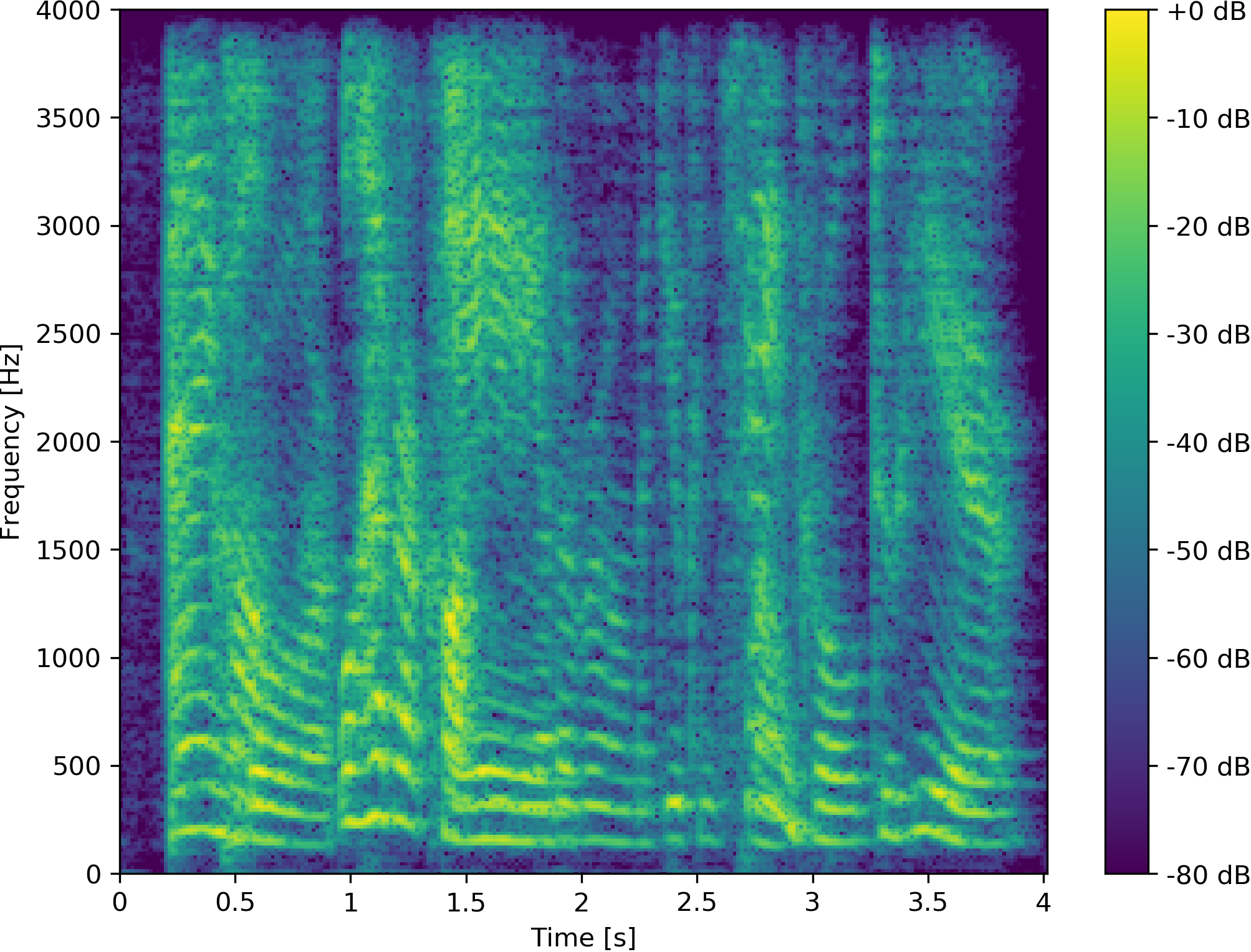
Example 2: Speaker vs. Non-Speaker
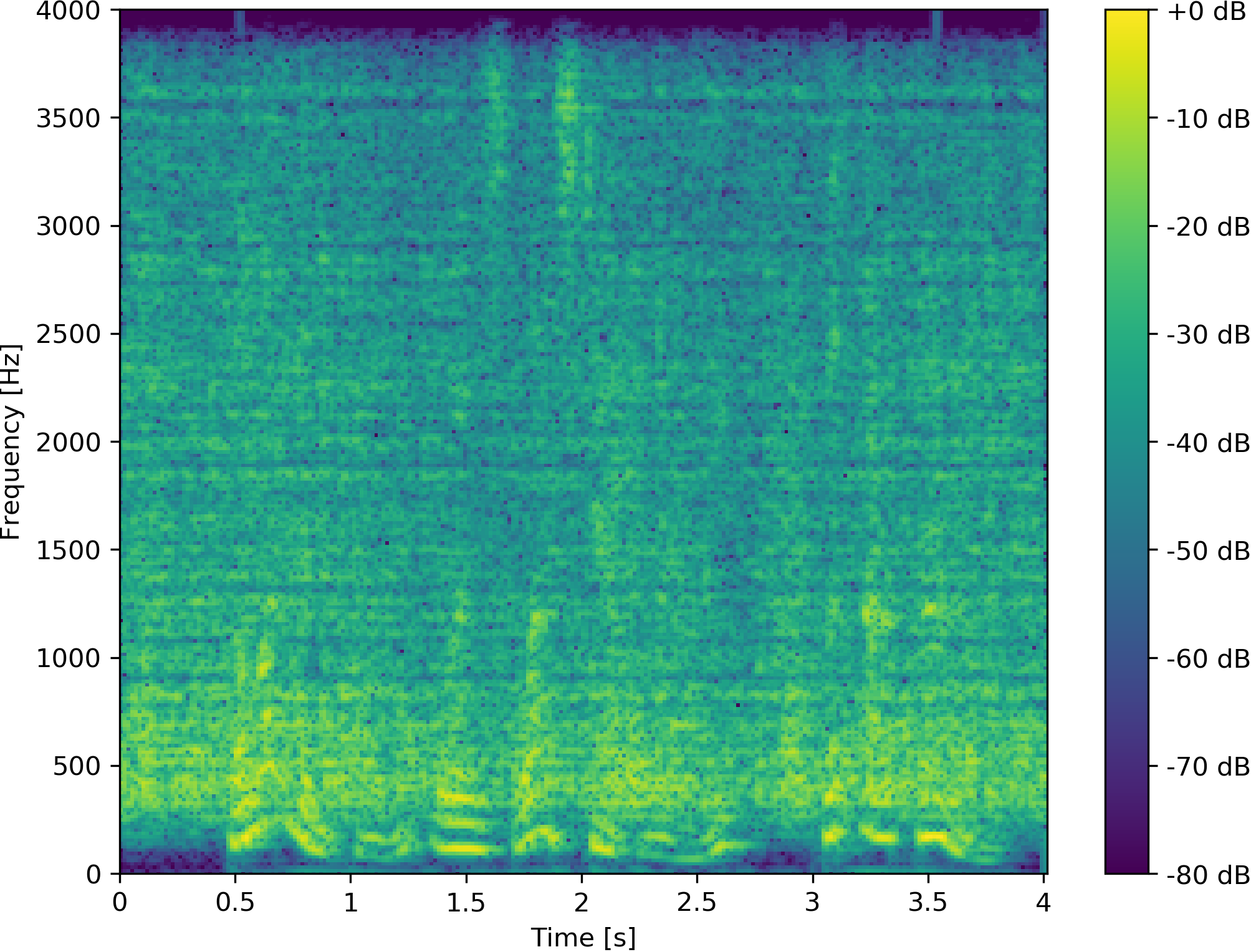
Example 3: Non-Speaker vs. Speaker
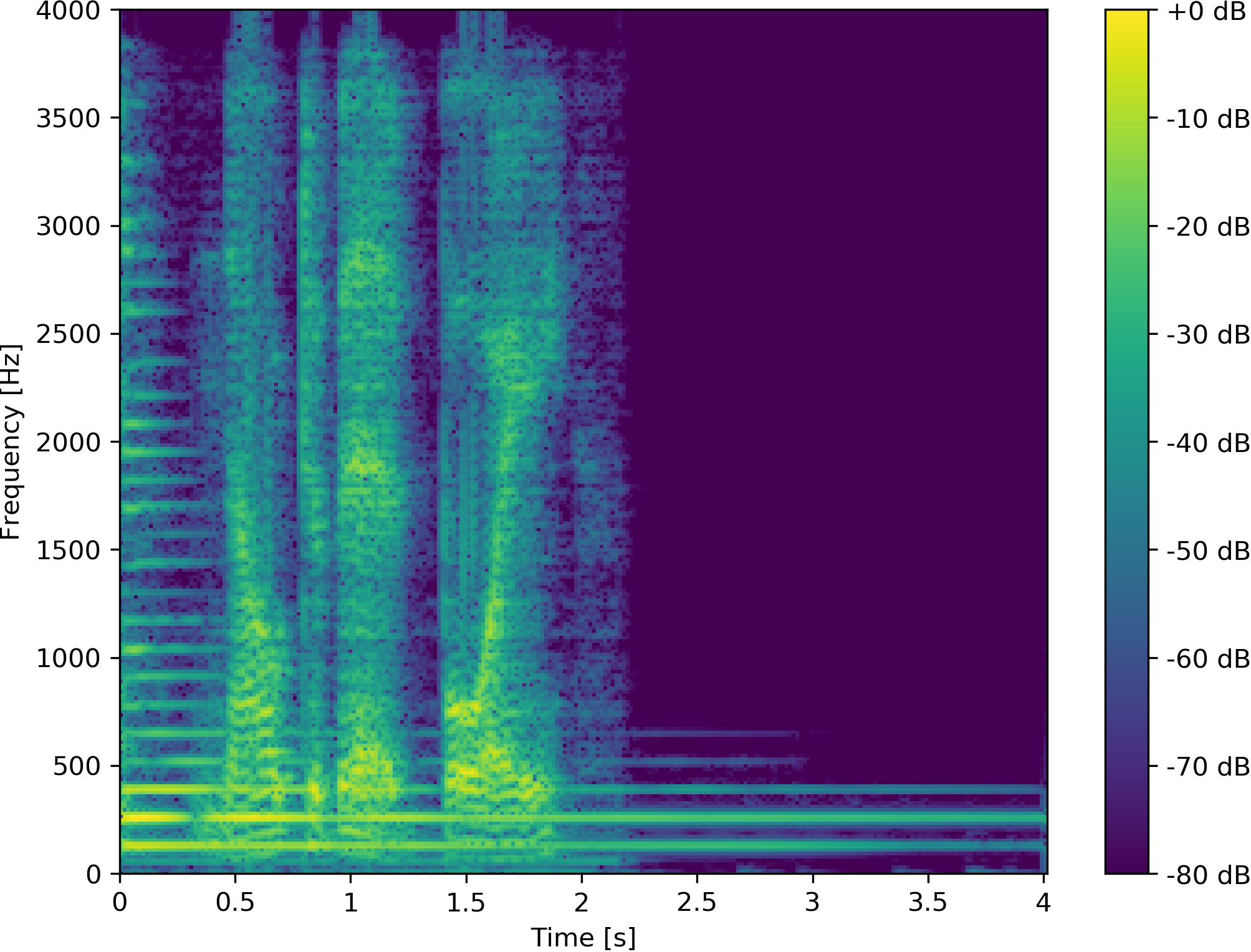
Example 4: Non-Speaker vs. Non-Speaker
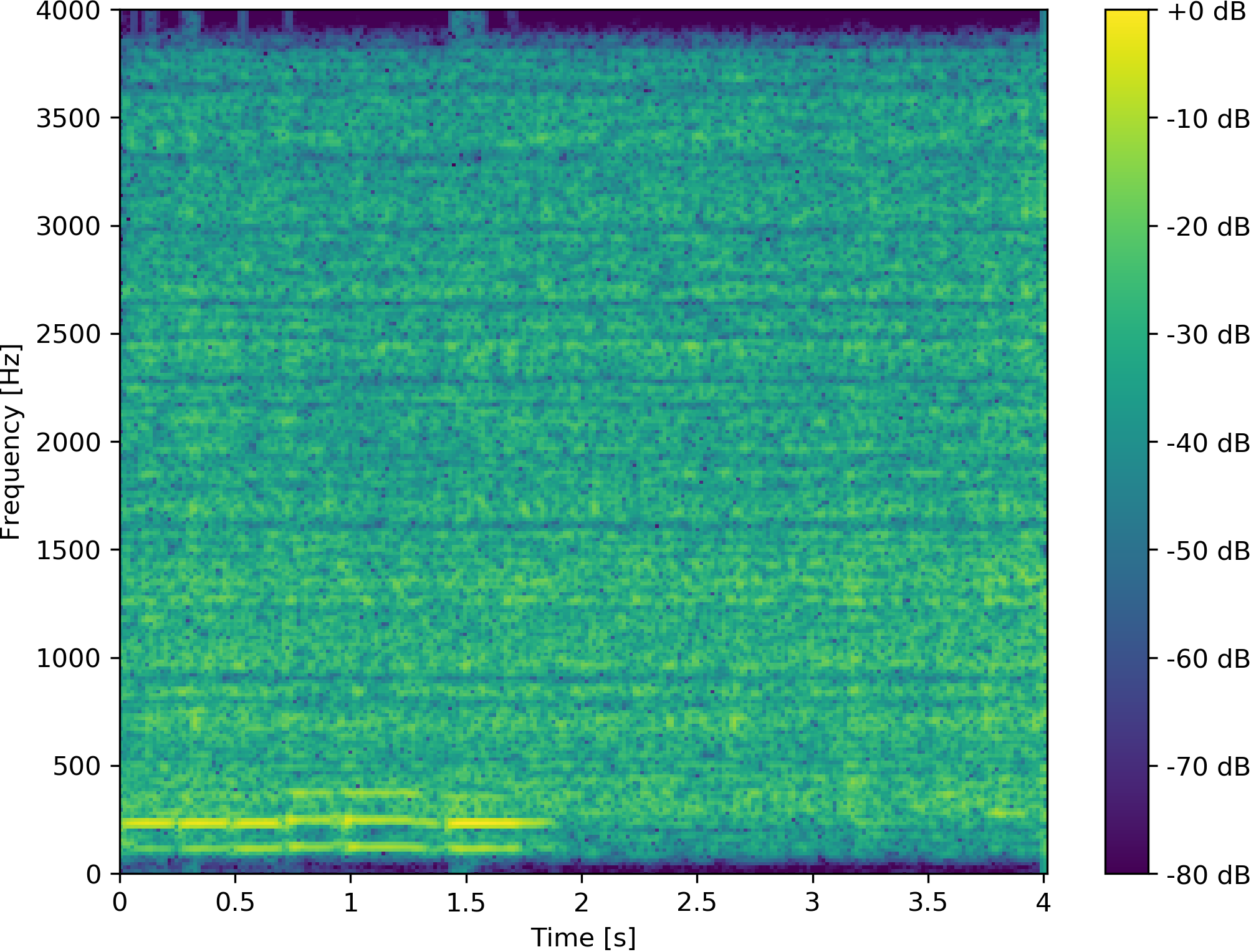
Example 5: Reference change after 2 s from speaker 1 to speaker 2
References
[1] M. Delcroix, T. Ochiai, K. Zmolikova, K. Kinoshita, N. Tawara, T. Nakatani, and S. Araki, “Improving speaker discrimination of target speech extraction with time-domain speakerbeam,” in Proc. IEEE Intl. Conf. on Ac., Sp. and Sig. Proc. (ICASSP), 2020, pp. 691–695.
[2] H. Zhang and D. L. Wang, “Deep learning for acoustic echo cancellation in noisy and double-talk scenarios,” in Proc. Interspeech Conf., 2018, pp. 3239–3243.