

Spatial Coherence-aware Multi-Channel Wind Noise Reduction
D. Mirabilii and E. A. P. Habets
Published in the IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020.
Abstract
Outdoor recording is particularly challenging in the presence of wind, which induces highly non-stationary noise in the microphone signals. To enhance a desired signal, e.g., speech, a dedicated noise reduction processing is required. The reduction is usually performed by estimating an unknown set of parameters, e.g., the noise and the speech power spectral densities (PSDs). In this paper, we focus on multi-channel wind noise reduction using closely-spaced microphones. In contrast to the commonly used assumption of uncorrelated wind noise, we assume the spatial correlation of wind noise contributions to be non-zero at low frequencies. In particular, we consider the spatial properties of wind noise when measured with closely-spaced microphones by employing a fluid-dynamics model, namely the Corcos model. The latter depends on the free-field speed and direction of the air stream, along with the microphone distance and the frequency. In our earlier work [1], we exploited the Corcos model to approximate the spatial coherence of wind noise by assuming an oracle wind speed and direction. The wind noise and speech PSDs were estimated by means of the approach presented in [2]. In this work, we propose a method to recursively estimate the spatial coherence matrix. In addition, we prove the equivalence of two recently developed noise PSD estimation methods when uncorrelated wind noise is assumed, and we propose an approximation of both estimators which is independent of the propagation vector of the speech source at low frequency when closely-spaced microphones are employed. An evaluation in terms of improvements in speech quality, signal-to-noise ratio and intelligibility is carried out using both synthetic and measured wind noise samples and compared to an existing multi-channel reduction approach which assumes uncorrelated wind noise [4].
Audio Examples
The following audio examples are the outcome of the experiments described in Section VI.B (generated wind noise) and VI.C (measured wind noise), respectively.
The processing scheme are the following:
- ML-based MVDR: minimum-variance-distortionless response beamforming based on the maximum-likelihood PSD estimators [4]
- FN-based MVDR: minimum-variance-distortionless response beamforming based on the Frobenius norm PSD estimators and oracle spatial coherence
- EM-based MVDR: minimum-variance-distortionless response beamforming based on the Frobenius norm PSD estimators and EM spatial coherence estimator
- ML-based MWF: multi-channel Wiener filter based on the maximum-likelihood PSD estimators [4]
- FN-based MWF: multi-channel Wiener filter based on the Frobenius norm PSD estimators and oracle spatial coherence
- EM-based MWF: multi-channel Wiener filter based on the Frobenius norm PSD estimators and EM spatial coherence estimator
- ML-based PMWF: parametric multi-channel Wiener filter based on the maximum-likelihood PSD estimators [4] + proposed trade-off parameter
- FN-based PMWF: parametric multi-channel Wiener filter based on the Frobenius norm PSD estimators and oracle spatial coherence
- EM-based PMWF: parametric multi-channel Wiener filter based on the Frobenius norm PSD estimators and EM spatial coherence estimator (proposed approach)
Example 1: Synthetic wind noise
The number of microphone used is four (ULA). The wind noise samples were generated by the simulation approach presented in [5]. The direction of arrival of the speech was assumed to be known. The wind noise contributions exhibit a spatial coherence approximated by the Corcos model with the following parameters:
- inter-sensor distance of 4 mm
- convective turbulence speed of 10 km/h
- stream direction of 0° with respect to the microphone axis
The speech was convolved with the RDTF in the broad-side position and mixed with the generated wind noise at 0 dB of input signal-to-noise ratio.
Note: Please use the Chrome or Safari browser for optimal audio/video synchronization. If you encounter playback problems, please reload the page.
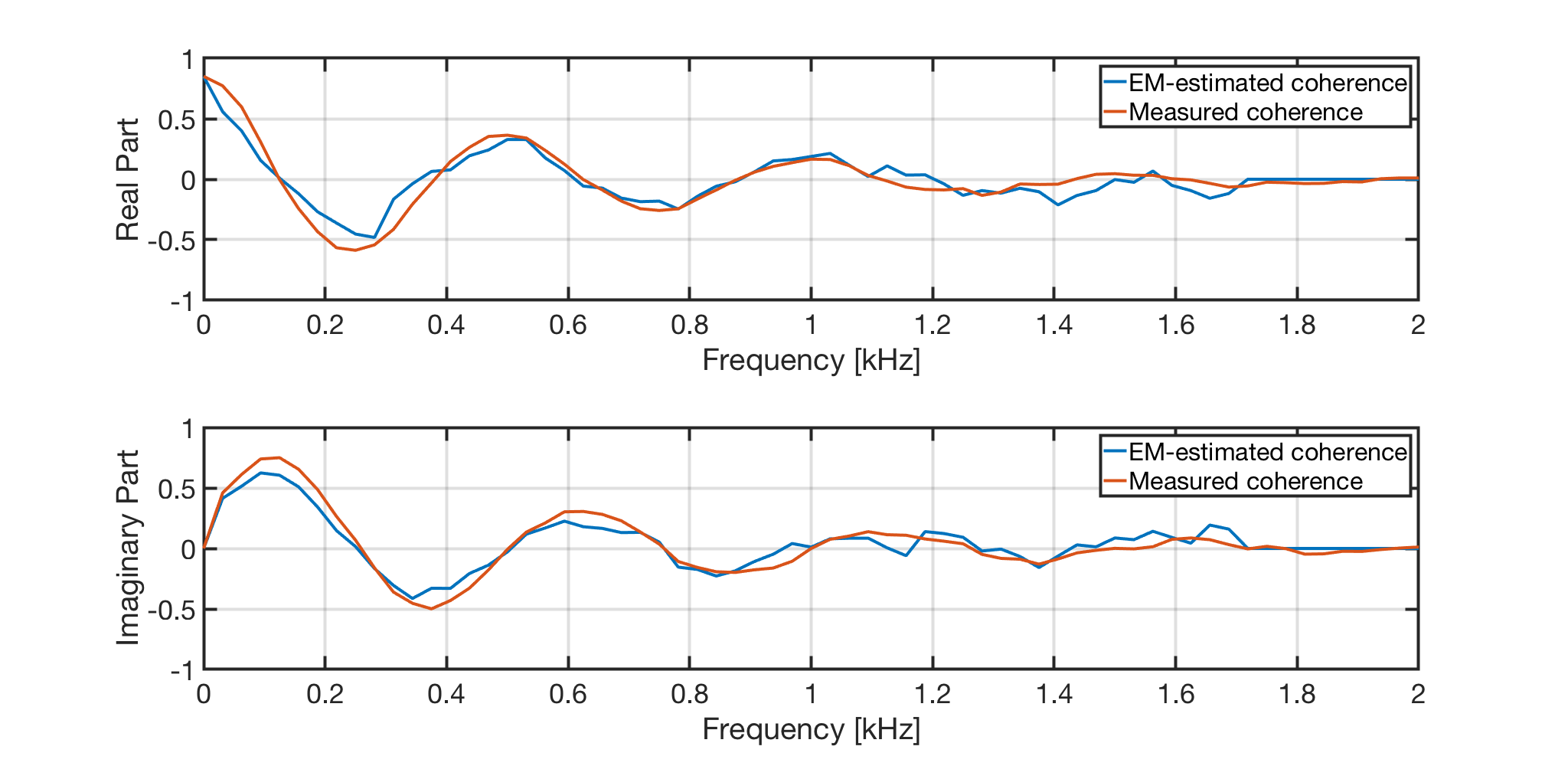
Following, the comparison between the spatial coherence measured from one microphone pair (in red) and the spatial coherence estimated exploiting the proposed method (in blue) from the example above
Example 2: Measured wind noise
The number of microphone used is three (CLA) with a radius of 0.7 cm. The wind noise samples were measured in the Negev desert (Israel). The direction of arrival of the speech is assumed to be known.
The IRs of the microphones were measured using pseudo-random excitations in a large room. We extracted the direct-path responses by truncating the IRs before the reception of the early reflections to simulate outdoor conditions. The speech was convolved with the truncated IR (broad-side position) and mixed with the measured wind noise at 0 dB of input signal-to-noise ratio.
The processing scheme are the same of the example 1, where the FN-based approach was excluded due to the lack of prior information on the wind speed and direction.
Note: Please use the Chrome or Safari browser for optimal audio/video synchronization. If you encounter playback problems, please reload the page.
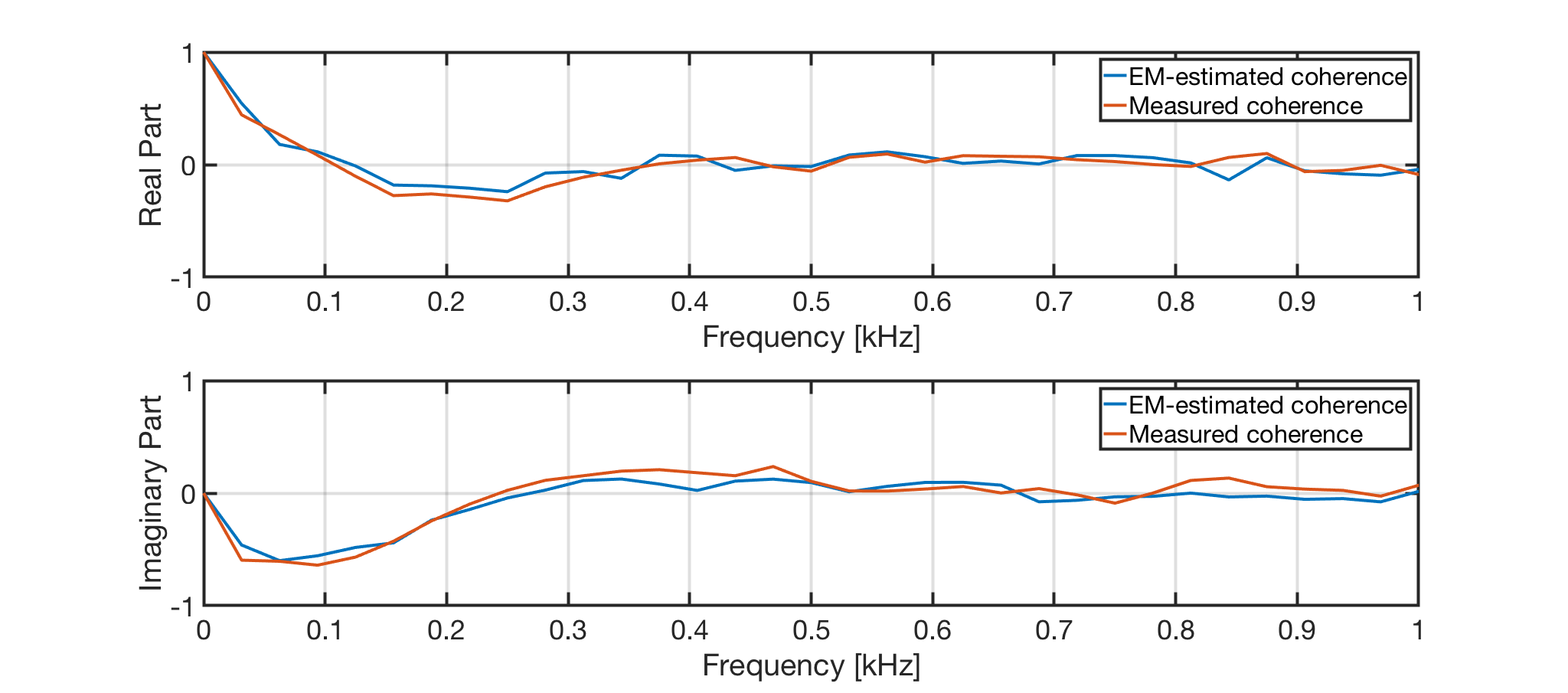
Following, the comparison between the spatial coherence measured from one microphone pair (in red) and the spatial coherence estimated exploiting the proposed method (in blue) from the example above
References
-
D. Mirabilii and E. A. Habets, Multi-channel wind noise reduction using the Corcos model, in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2019. [Audio Examples]
-
O. Schwartz, S. Gannot, and E. A. Habets, Joint estimation of late reverberant and speech power spectral densities in noisy environments using Frobenius norm, in Proc. European Signal Processing Conf. (EUSIPCO), 2016.
-
D. Mirabilii and E. A. P. Habets, On the difference-to-sum power ratio of speech and wind noise based on the Corcos model, in Proc. IEEE Intl. Conf. on the Science of Electrical Engineering (ICSEE), 2018.
-
P. Thuene and G. Enzner, Maximum-likelihood approach to adaptive multichannel-wiener postfiltering for wind-noise reduction*, in Proc. of the ITG Conference on Speech Communication, pp. 1–5, VDE, 2016.
-
D. Mirabilii and E. A. Habets, Simulating multi-channel wind noise based on Corcos model, in Proc. Intl. Workshop Acoust. Echo Noise Control (IWAENC), 2018. [Code]