

Minimum Bayes Risk Signal Detection for Speech Enhancement Based on a Narrowband DOA Model
Maja Taseska and Emanuel A. P. Habets
Published in the Proc. of the IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia 2015.
Abstract
A desired speech signal in hands-free communication systems is often degraded by background noise and interferers. Data-dependent spatial filters are state-of-the-art in multichannel signal enhancement, where the required power spectral density (PSD) matrices are often estimated recursively, using a signal model-based speech presence probability (SPP). The SPP and the resulting PSD matrices are only accurate, if the statistics of the undesired signals change more slowly over time compared to the desired signal. In practical situations with competing talkers, this assumption is violated. To estimate the PSD matrices of highly non-stationary signals, we propose a minimum Bayes risk detector based a model for the narrowband direction-of-arrival estimates. The detector leads to accurate PSD matrix estimates for the desired and the undesired signals in various challenging acoustic conditions. Performance evaluation is presented using simulated and measured data, demonstrating successful extraction of the desired speech signal.
Description
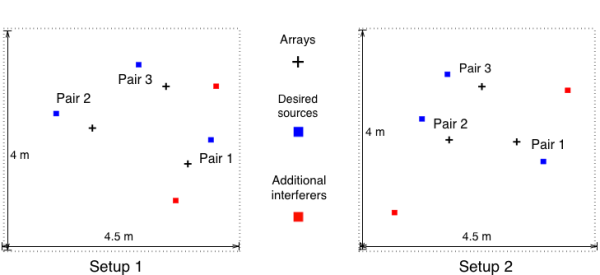
Measurements were carried out in a room with reverberation time approximately T60 = 160 ms, for the two setups shown below. To extract a desired source, we used a uniform circular array with three omnidirectional DPA microphones. In each scenario there are three source-array pairs, where the array is used to extract the corresponding source while reducing interferers and background noise. Each source was extracted using a minimum variance distortionless response (MVDR) filter with the three microphones from the corresponding array. Note that no post-filtering techniques are applied, and the achieved noise and interference reduction is obtained only by using spatial information. The PSD matrices were estimated recursively, where different detectors were used to determine whether the desired or the undesired signal is dominant at a given time-frequency bin.
Detectors compared in the evaluation:
- Ideal detector: Oracle knowledge whether the desired or the undesired signal is dominant in a given time-frequency bin.
- Signal model-based detector: Signal model-based detector with DOA-based a priori SPP [1] is used to determine whether the desired or the undesired signal is dominant in a given time-frequency bin.
- Proposed detector: The proposed detector is used to determine whether the desired or the undesired signal is dominant in a given time-frequency bin.
Audio Examples
Setup 1, triple talk plus background noise
Source 1 at reference microphone: