

Experiments/Demos
SEFGAN: Harvesting the Power of Normalizing Flows and GANs for Efficient High-Quality Speech Enhancement
Link: Demo
| This paper proposes SEFGAN, a Deep Neural Network (DNN) combining maximum likelihood training and Generative Adversarial Networks (GANs) for efficient speech enhancement (SE). For this, a DNN is trained to synthesize the enhanced speech conditioned on noisy speech using a Normalizing Flow (NF) as generator in a GAN framework. While the combination of likelihood models and GANs is not trivial, SEFGAN demonstrates that a hybrid adversarial and maximum likelihood training approach enables the model to maintain high quality audio generation and log-likelihood estimation. Our experiments indicate that this approach strongly outperforms the baseline NF-based model without introducing additional complexity to the enhancement network. A comparison using computational metrics and a listening experiment reveals that SEFGAN is competitive with other state-of-the-art models. |
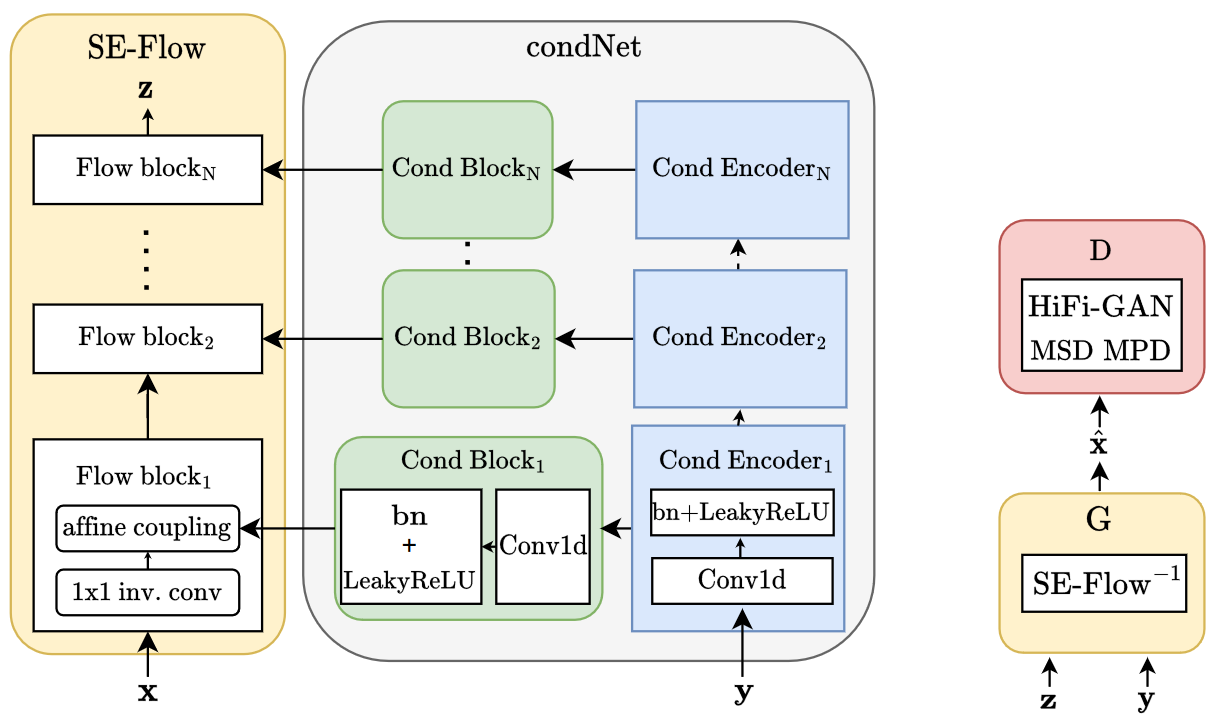
|
Improved Normalizing Flow-Based Speech Enhancement Using an All-Pole Gammatone Filterbank for Conditional Input Representation
Link: Demo
| Deep generative models for Speech Enhancement (SE) received increasing attention in recent years. The most prominent example are Generative Adversarial Networks (GANs), while normalizing flows (NF) received less attention despite their potential. Building on previous work, architectural modifications are proposed, along with an investigation of different conditional input representations. Despite being a common choice in related works, Mel-spectrograms demonstrate to be inadequate for the given scenario. Alternatively, a novel All-Pole Gammatone filterbank (APG) with high temporal resolution is proposed. Although computational evaluation metric results would suggest that state-of-the-art GAN-based methods perform best, a perceptual evaluation via a listening test indicates that the presented NF approach (based on time domain and APG) performs best, especially at lower SNRs. On average, APG outputs are rated as having good quality, which is unmatched by the other methods, including GAN. |
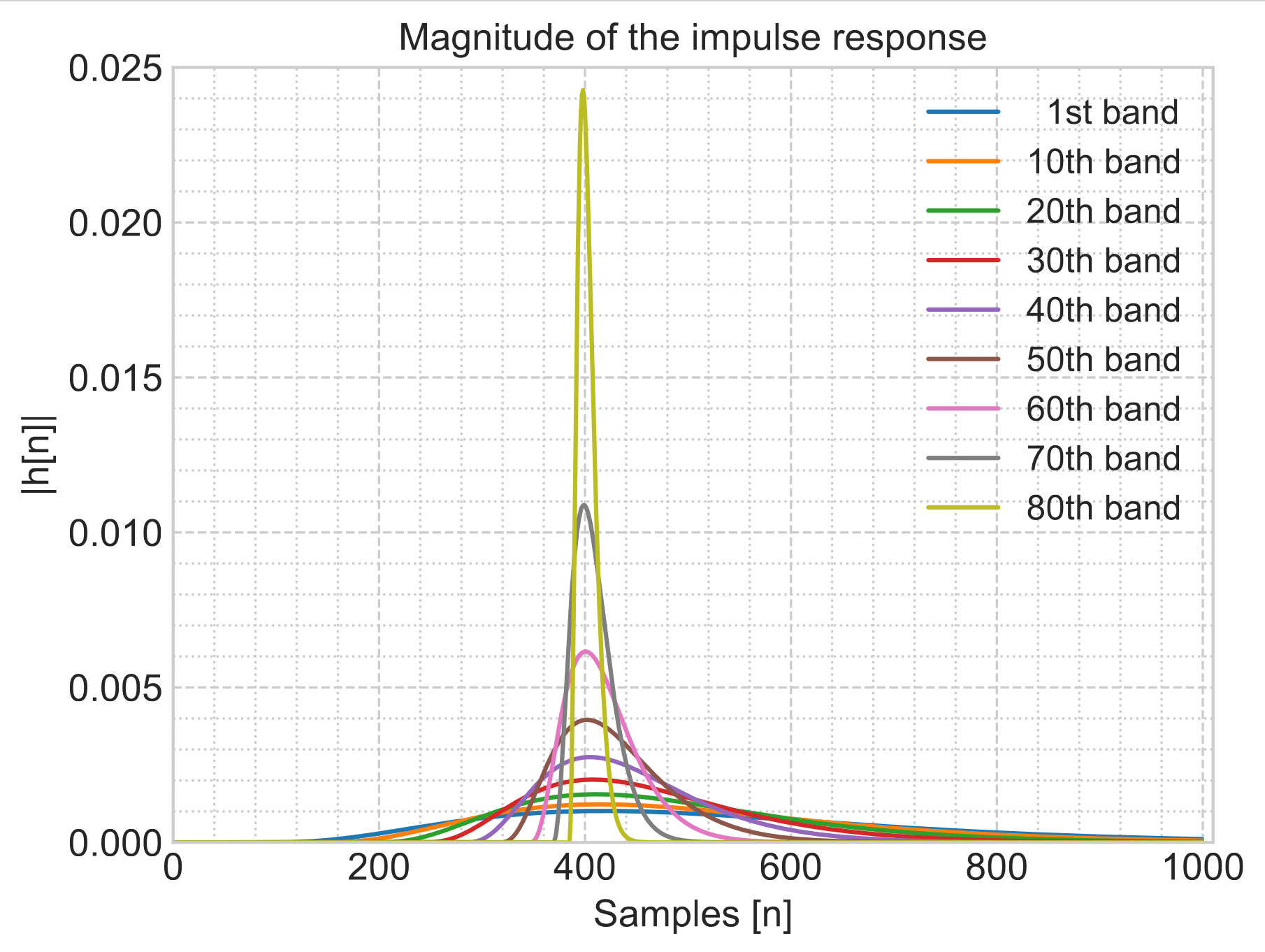
|
A flow-based neural network for time domain speech enhancement
Link: Demo
| Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding helps to improve the model performance by expanding the range of learnable values. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics. |
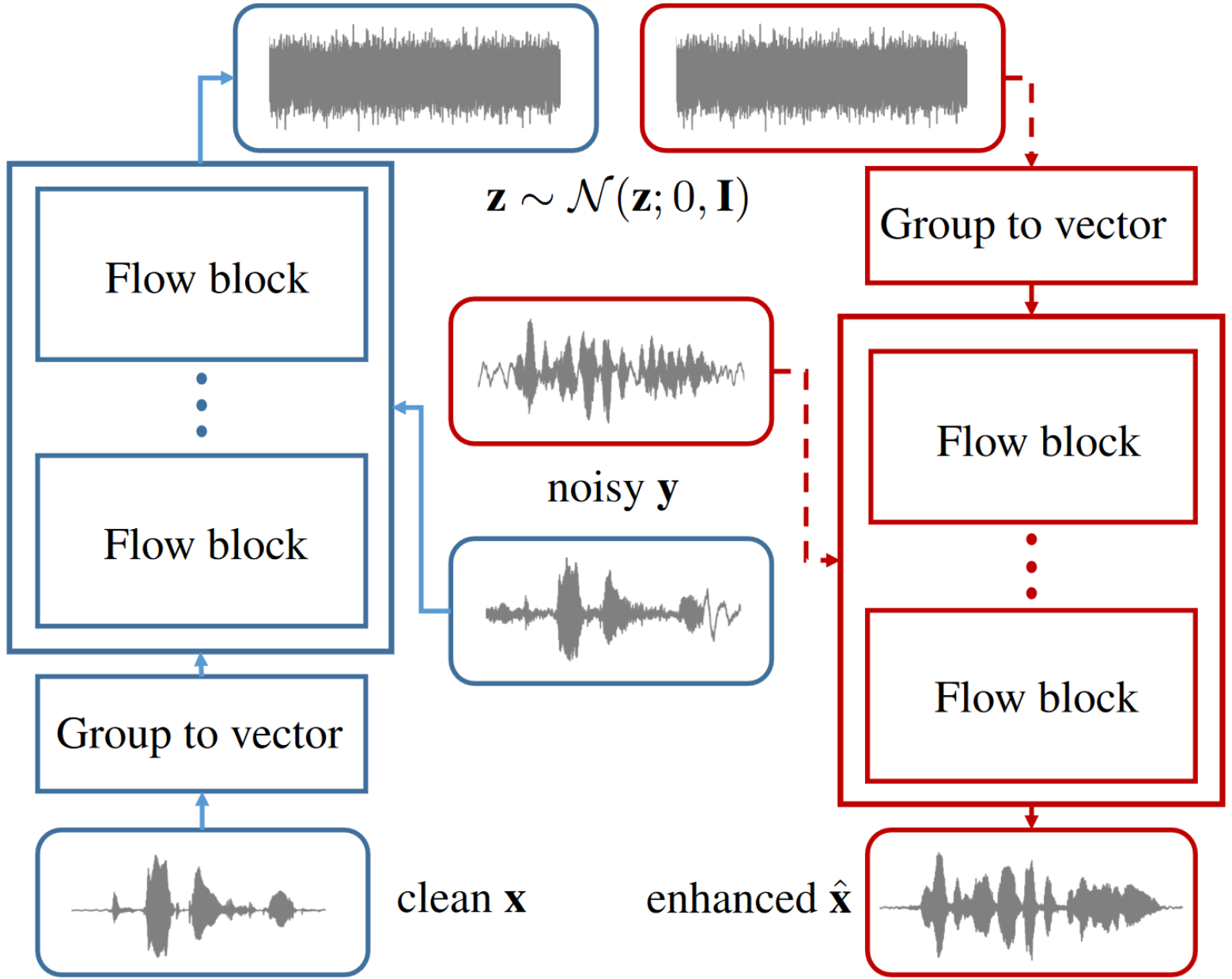
|